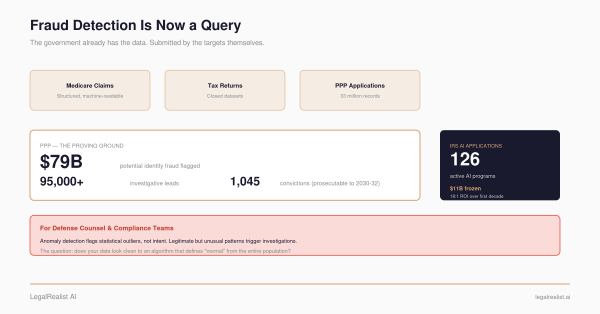
Medicare claims, tax returns, PPP and EIDL applications — the government increasingly holds the structured transaction data that lets fraud enforcement start with a query, not a tip.
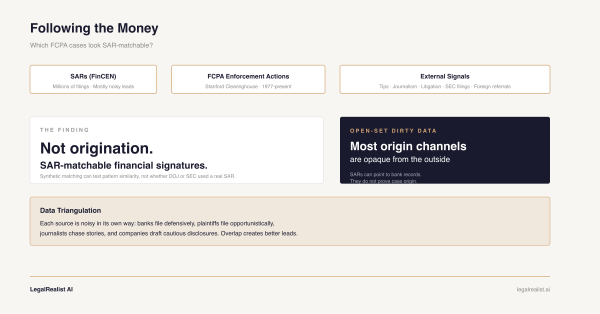
A proof of concept for using AI and synthetic SAR data to estimate how many FCPA enforcement actions describe transaction patterns that would plausibly generate suspicious activity reports — and what that tells us about the hidden plumbing of anti-corruption enforcement.
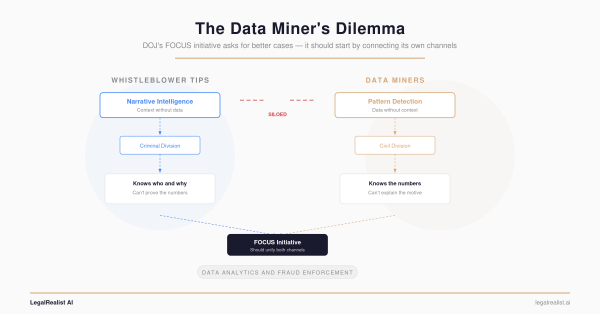
DOJ's new FOCUS initiative wants better data-driven fraud cases. But it keeps its two best enforcement channels — whistleblower tips and data miner analytics — in separate silos. The real opportunity is connecting them.
Public PPP data can produce enforcement-relevant anomaly maps. An open-source fraud-scoring system, run against the SBA PPP dataset, surfaced lender and geographic concentrations that overlap with known enforcement patterns — while also showing why public data cannot prove fraud by itself.
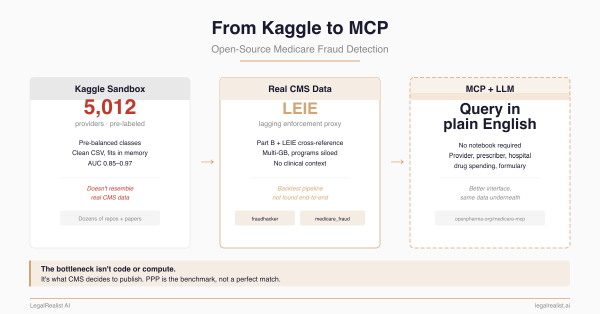
The PPP fraud pipeline worked because the SBA released unusually inspectable data. Medicare's public data is fragmented, de-identified, and missing the features detection needs. Here's what exists on GitHub, where it falls short, and what CMS would need to release to make outside healthcare-fraud analysis more practical.
The previous post described a Medicare fraud backtest nobody had built. Here are the results. 289 excluded providers across 41 states, matched to pre-exclusion billing data, compared against 3.39 million peers. Thirteen of fifteen features showed statistically significant differences — and the same behavioral fingerprint shows up in never-excluded providers who have independent enforcement histories.
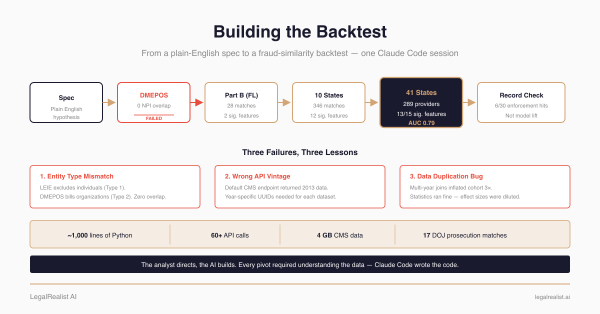
A walkthrough of building a Medicare fraud backtest overnight in Claude Code — from a plain-English spec to 289 matched providers across 41 states, a fraud-similarity model with AUC 0.79, and a manual public-record check of high-scoring peers. Including the three times the pipeline failed, the data duplication bug, and the engineering decisions that shaped the final design.